Le enseñé a un LLM a no decir nada la mayor parte del tiempo.
Semana 3 de una serie build-in-public de 10 semanas. La data stack — y por qué la mitad ruidosa es donde el sistema gana o se rompe.


Hace una semana dije que esta cosa ya no era un agente apostador — era una arena donde construís agentes y los hacés competir entre sí. Los agentes son el frente del local. Este post es sobre el fondo: los datos que ven, y el mecanismo que le permite a cada agente aprender con el tiempo de sus propias decisiones — como lo haría un humano.
La versión que sobrevivió tiene agentes simulados, cada uno con su propia parametrización, que hacen una llamada a Claude por cada juego del slate. La mayor parte del tiempo, esa llamada vuelve diciendo nada. No es un bug. Es el diseño.
Tres semanas adentro
Antes de meternos en el back-end, esto es donde están parados los agentes después de las primeras tres semanas de paper-trading.
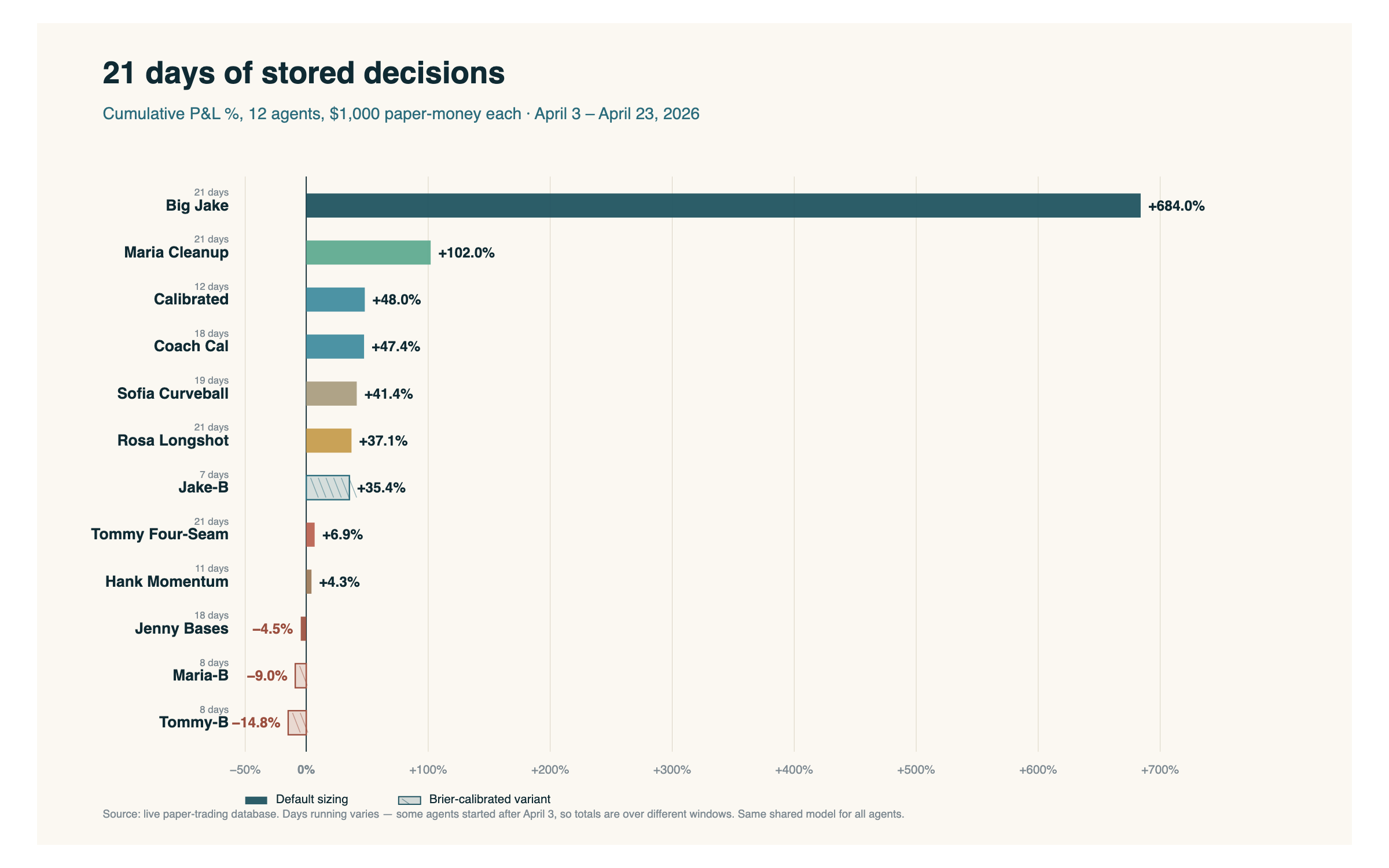
12 agentes, el mismo modelo compartido detrás de todos ellos, distintas reglas de sizing y selección. Algunos agentes arrancaron después del 3 de abril, así que sus totales son sobre ventanas más cortas — esa es la nota de back-calc, marcada en el chart por honestidad. La corrida de Big Jake es la historia ruidosa. La parte de abajo de la tabla — el mismo modelo compartido, números negativos reales — es la silenciosa.
El resto de este post es sobre el back-end que produce esos números: los datos que los agentes ven, y el mecanismo que le permite a cada uno aprender con el tiempo de sus propias decisiones.
Las dos mitades que los agentes tienen que combinar
Cada agente tiene que combinar dos tipos muy distintos de inputs para hacer una jugada.
Estructurado. Box scores, stats rolling, odds, clima, ratings. Números entran, números salen. Schemas estables, aritmética honesta, un ensemble de XGBoost al final de la línea.
No estructurado. Notas de beat-writers, partes médicos, tweets de alineaciones, transacciones. Ruidoso de una manera que no se puede schematizar — la mayoría de las "noticias" son chamuyo, la señal genuina es rara, y un sistema que trata cada titular como material termina sacudido como un trapo.
El juego entero es combinar las dos. El lado estructurado le da al agente una probabilidad. El lado no estructurado o la confirma o silenciosamente le dice al agente que baje el sizing.
Esta es la parte que genuinamente me asombra de la generación actual de IA. Cribar a través de una pila de texto mayormente ruido — takes de beat-writers, tweets de alineaciones, logs de transacciones — para encontrar el único dato que importa para un juego específico es el tipo de trabajo que antes o requería un analista por slate o directamente no se hacía. Lo que quiero que notes acá no es una afirmación sobre lo bueno que el modelo es haciéndolo — si está encontrando los diamantes correctos, y con qué frecuencia, es exactamente lo que estoy midiendo. Es que el modelo es lo suficientemente rápido y barato como para intentar el trabajo sistemáticamente con un presupuesto de finanzas personales: cada juego, cada día, en segundos, por centavos. La capacidad es alcance operativo, no juicio probado. El juicio es lo que el resto del sistema está construido para mantener honesto.
Dónde corre todo esto
Antes de meternos en cualquiera de las dos mitades, vale la pena decir dónde vive todo esto, porque es deliberadamente simple.
El back-end entero son dos cosas:
- Una base de datos Postgres en Railway (una plataforma cloud amigable para hostear apps y bases de datos), con la extensión
pgvectoractivada para que la misma base pueda guardar tanto tablas relacionales como vectores de embeddings. - Un proceso Python que corre todo lo demás — un único servicio web cuyo entry point arranca un scheduler en background y un dashboard chico en foreground. APScheduler es el cron-equivalente adentro del proceso; dispara los jobs diarios en un heartbeat fijo en UTC.
Eso es todo. Sin microservicios, sin colas de mensajes, sin workers separados. El pipeline entero — buscar las stats del día, buscar las noticias del día, armar los feature vectors, correr las predicciones del modelo, sintetizar la señal no estructurada, evaluar a cada agente contra cada juego, loguear cada decisión — corre como una secuencia de jobs adentro de ese único proceso, en el mismo orden, todos los días.
Hay una razón para la simplicidad más allá del costo. Cuando el back-end entero es un proceso y una base de datos, cada problema tiene exactamente un lugar donde mirar. La mayor parte de la fricción en este proyecto fue sobre tomar decisiones limpias, no sobre debuguear plomería distribuida.
Mi filosofía como builder es mantener las cosas simples. O tan simples como las pueda hacer.
La mitad estructurada
Un puñado de fuentes gratuitas o casi gratuitas le dan de comer a este lado: la MLB Stats API oficial para el calendario, las alineaciones y stats a nivel equipo; The Odds API para las odds del mercado en vivo; Open-Meteo para el clima a la hora del juego; y logs históricos de juegos para el entrenamiento y los cómputos rolling.
El pipeline transforma esas en 90+ inputs por juego — básicamente cada cosa cuantificable que un fan serio pensaría en mirar antes de un juego, más algunas que no.
Hay una decisión de diseño acá que vale la pena flaggear porque es el tipo de cosa que silenciosamente destroza modelos: cada feature se computa estrictamente a partir de datos disponibles antes del juego. Sin lookahead. El loop de entrenamiento es walk-forward — entrenar sobre el primer batch de juegos, predecir el siguiente, deslizar adelante, reentrenar. Es más lento y se ve menos impresionante en backtests que la alternativa, y por eso mismo funciona.
La mitad difícil (las noticias)
La capa no estructurada es la parte donde la mayoría de los proyectos de "IA en deportes" o saltean el laburo o agitan los brazos. Acá hace trabajo real, pero de un tipo deliberadamente angosto.
Un job programado tira noticias de un set chico de fuentes confiables dos veces por día, en la ventana antes de que las líneas pre-game se firmen. Los artículos se embeben y se guardan junto con el resto de los datos, así para cualquier juego dado el sistema puede agarrar el puñado de items que efectivamente mencionan a los equipos o lanzadores involucrados.
Después, para cada juego del slate, Claude lee ese pequeño bundle y responde exactamente una pregunta: dado lo que el modelo estructurado ya sabe, ¿esta noticia amerita ajustar la confianza con la que actuaríamos sobre la decisión del modelo?
La respuesta no es un pick. No es una probabilidad. Es una pequeña señal estructurada que puede dejar la decisión del modelo intacta, escalarla hacia abajo, o en casos extremos detenerla por completo. El LLM no puede elegir un lado. Solo puede atenuar.
El diseño conservador
La capa entera es conservadora a propósito. El diseño se construye alrededor de una idea: la mayoría de las noticias no son noticias, y un modelo que no sabe cómo ignorar el ruido es solo ruido.
Así que el LLM tiene autoridad angosta. No puede fortalecer una decisión, solo reducirla o bloquearla. La reducción máxima es chica — una fracción, no un giro. Y su estado por defecto es silencio: si no hay una razón clara y material para decir algo, la respuesta correcta es no decir nada.
La memoria del agente es parte del data stack
Esta es la parte más divertida de pensar, y es uno de los aprendizajes inesperados más grandes del experimento hasta ahora.
La misma base de datos también guarda qué decidió cada agente, por qué, y qué pasó. Cada vez que un agente evalúa un juego — pick o skip — se inserta una fila: qué agente, qué juego, la señal estructurada, la señal no estructurada, la decisión, un campo de texto libre breve resumiendo la jugada, y (rellenado después del settlement) el resultado.
Los skips importan tanto como los picks. Ahí es donde la mayoría de los sistemas pierden la memoria.
Esta fue una decisión que tuve que tomar: ¿guardar cada decisión de juego, o solo las que el agente eligió? A fin de cuentas esto es un experimento. Quiero probar tantas cosas como sea posible con IA en el loop — IA y yo, los dos aprendiendo a la par. Y para que la IA aprenda, una cosa que necesitás es buena data, y mucha. Así que estoy guardando los juegos skip también, como fuente de aprendizaje. La idea no es solo asegurarnos de haber elegido los juegos correctos (verdaderos positivos) — es también minimizar la chance de no elegir uno bueno (falsos negativos). Esa es la otra mitad que estoy tratando de capturar guardando cada decisión, de cada agente.
El reframe
La mayor parte de la conversación alrededor de los LLMs gasta un montón de tiempo en lo que no pueden hacer: no recuerdan a través de llamadas, no aprenden de los resultados, no acumulan experiencia como lo haría una persona. Trabajar en este experimento me hizo pensar que esas no son limitaciones — son oportunidades. El modelo no tiene que recordar nada si el sistema alrededor lo hace. La memoria del agente no tiene que vivir adentro del modelo. Puede vivir en una base de datos vectorial, y le pasás la rebanada relevante de vuelta al modelo en el momento de la decisión.
En otras palabras, la idea del experimento es: construí la parte que el LLM no tiene, y el LLM termina usándola como si la hubiera tenido siempre. Eso es. Esa es la hipótesis del "Unlock".
Una dirección que quiero explorar
Si un agente puede aprender de su propio track record de esta manera, ¿por qué no podría un agente aprender del de otro? Todos trabajan para la misma persona. No hay razón por la que Big Jake no pueda compartir una lección ganada a los golpes — "este tipo de juego parece un layup pero me sigue agarrando" — con otro agente del roster. El sustrato es el mismo; solo tendrías que decidir qué cuenta como conocimiento transferible y qué es específico al estilo de un agente.
Eso no está construido. Está en el research queue. Pero es el tipo de sinergia que solo tiene sentido una vez que la capa de memoria existe en primer lugar — y la capa de memoria es de lo que se trata toda esta sección.
Por qué el split funciona
Dos razones.
Separación de responsabilidades. El modelo estructurado es responsable de "cuál es la probabilidad de que este equipo gane, dado todo lo cuantificable". El LLM es responsable de "¿hay información cualitativa confirmada que el modelo no podía ver?". Son trabajos distintos y deberían tener autoridades de decisión distintas. El modelo elige. El LLM solo objeta.
Auditabilidad. Cada resultado de síntesis se guarda. Cada decisión se guarda con los inputs que la motivaron. Cuando algo funciona o se rompe, puedo leer exactamente qué pensaba el sistema que estaba viendo. Los prompts y los thresholds se editan al contacto con la realidad, no por intuición.
Cuánto cuesta todo esto
La mayoría de las fuentes de datos son gratis o casi (MLB Stats API, Open-Meteo, RSS), con NewsAPI en su tier dev gratuito. El único costo per-call material es la capa de síntesis de Claude a aproximadamente $0,13 por día para un slate completo de juegos — menos de $5 por mes para la pieza de LLM. Sumá la cuenta chica de Postgres + un único proceso web en Railway y el stack entero corre en menos de un sándwich por semana, no de un sándwich por día.
La semana que viene
El Post 4 es sobre trabajar con Claude Code como ingeniero principal en este proyecto. Hice una mención puntual más arriba a un momento donde Claude cargó peso real — la capa RAG conservadora-por-diseño sobre la que corre el sistema. La semana que viene es la foto completa: dónde la IA está genuinamente haciendo el trabajo, dónde estoy yo, y dónde la línea sigue moviéndose.
Si construiste algo con una forma parecida — modelo estructurado + LLM como filtro silencioso, más una capa de memoria para las decisiones del propio sistema — me gustaría comparar notas.
Posts anteriores de esta serie: Semana 1 — el origen · Semana 2 — el pivot (las pruebas).
Estas son notas personales de un side project que hago en mi propio tiempo con mis propios recursos. Las opiniones acá son mías y no están conectadas, endosadas ni representan a mi empleador ni ninguno de mis trabajos profesionales.



