Cómo intento mantener honesta a mi IA.
Semana 5 de una serie build-in-public de 10 semanas. Update del portfolio a 5 semanas, un audit independiente, y una nota corta sobre el lado de compliance de la misma semana.


El Post 4 fue sobre quién hizo qué en este proyecto. Esta semana es sobre si lo que se hizo está funcionando de verdad, y sobre chequear que los números que vengo posteando desde la Semana 3 son los números reales.
La versión corta: sí. Con un asterisco honesto al que voy a llegar.
Cinco semanas
Trece agentes en el chart esta semana — una fila más que en el Post 4. Dusty Ramirez ya estaba en el roster entonces, solamente con cero picks para dibujar. Ya voy a llegar a él. El mismo modelo compartido detrás de todos. Distintas reglas de sizing y de selección. Cinco semanas de paper-trading en el libro.
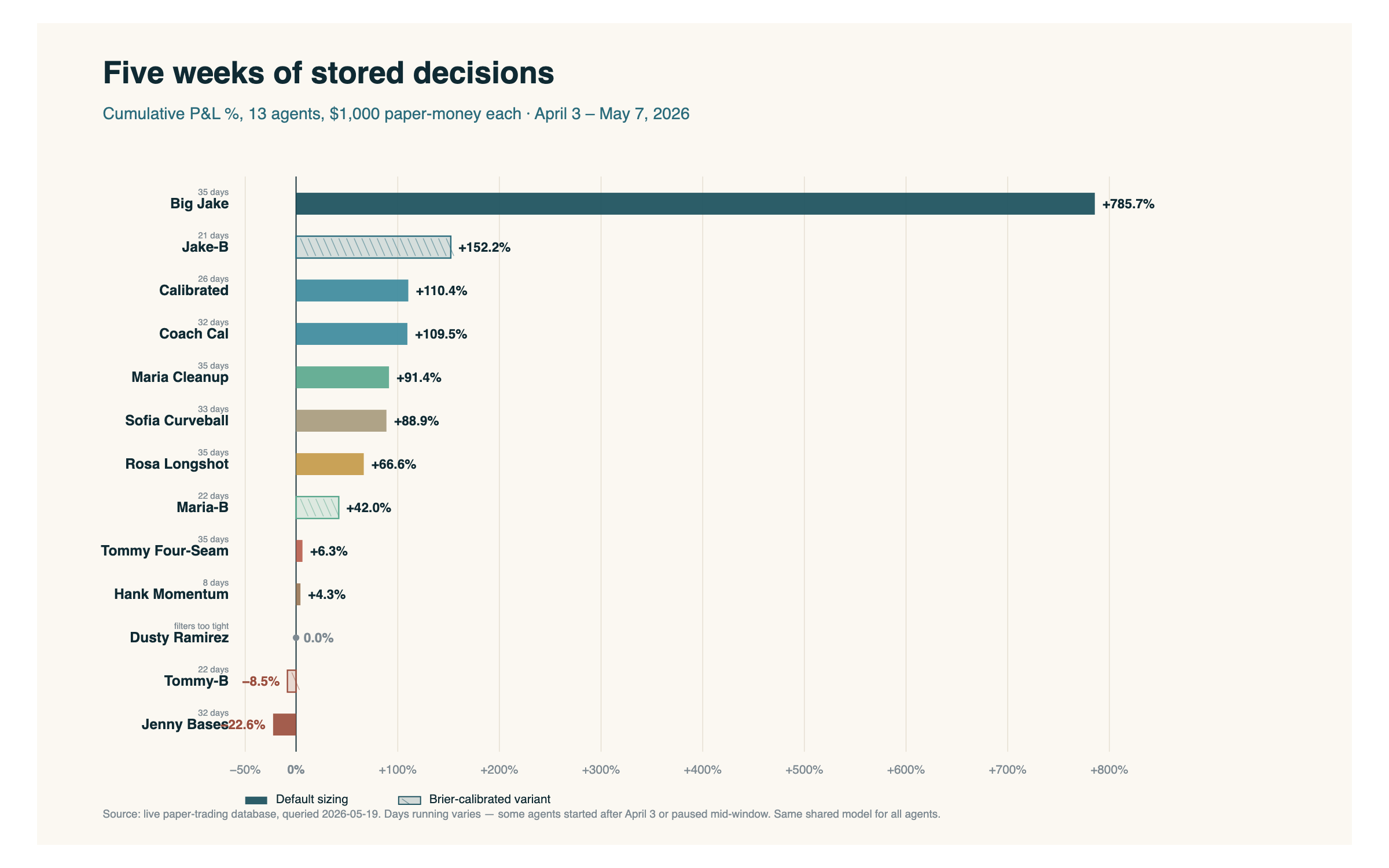
Algunas observaciones.
El portfolio en conjunto está arriba +$14.261 sobre $12.000 desplegados en 35 días — más o menos +119%. A través de los trece agentes, el sistema settleó 1.801 picks y skippeó 24.307. Eso es aproximadamente trece skips y medio por cada pick.
Big Jake amplió su ventaja a +786%. Sobre un bankroll inicial de $1.000 eso son $7.860 de paper-money, sobre un modelo compartido con los mismos inputs subyacentes que todos los demás. La historia ahí es sizing, no selección. Toma una posición más grande cuando ve un edge. El resto no.
Las variantes Brier maduraron. Jake-B ya tiene suficiente cantidad de días para sentarse segundo en el board (+152%), que es el tipo de resultado que las probabilidades calibradas por Brier están supuestas a producir sobre una muestra más larga. Las dos variantes de Tommy siguen sufriendo. Tommy-B es el único agente Brier en rojo.
Algunos agentes se están acomodando en el medio de la tabla. Maria Cleanup, Sofia Curveball y Rosa Longshot se movieron entre la Semana 4 y la Semana 5 — las muestras chicas son ruidosas y la regresión es real.
Dusty Ramirez es la nueva fila en el board, y el nuevo asterisco: lleva cero picks en seis semanas. Sus thresholds de filtro son tan apretados que nada en el slate califica. Eso es un bug real, no una estrategia. Fix en la lista.
Jenny Bases fue desactivada el 7 de mayo después de caer a −22,6%. Vale la pena decirlo en voz alta: los números negativos también son reales. El sistema no está curado. Cada agente que arrancó siguió corriendo hasta que tuve un motivo para frenar uno.
El sanity check que construí esta semana
Cerca del día cuarenta, me agarré dudando de mis propios números.
La matemática estaba bien. La aritmética estaba bien. El gráfico de portfolio que acabás de ver estaba bien. Pero estos números vienen todos de un sistema que construí yo. Los agentes son míos. El modelo que está detrás de ellos es mío. El settle job que decide quién ganó cada juego y escribe la fila de profit es mío. El dashboard donde leo mis propios resultados es mío. Cuatro veces "mío" seguidas, y yo estaba por seguir posteándolos, semana tras semana, como si fueran hechos.
Ese fue el momento en que decidí que necesitaba un chequeo de afuera.
Si venís siguiendo la serie, sabés que los agentes settlean sus picks a través de un job que llama al MLB Stats API por los resultados finales. Ese settle job decide quién ganó, llena el profit, y escribe la fila. El modelo. El settler. La historia. Todo adentro de un proceso, sobre una base de datos, que es mía.
Así que esta semana construí un módulo separado que audita todo desde afuera. Corre read-only. Saca cada pick settleado de la base de datos, le pregunta al scoreboard público de MLB de ESPN qué dice él sobre ese juego, y compara cuatro cosas:
- ¿El score coincide?
- ¿El ganador coincide?
- ¿Se jugó el partido hasta el final?
- Dado el score, nuestro flag de "won" — el campo que determina si el pick pagó — ¿está correcto?
ESPN importa acá porque es genuinamente independiente de mi pipeline. La fuente interna es MLB Stats API. Si cruzara contra esa misma fuente, estaría preguntándole lo mismo dos veces y llamando a la respuesta confirmación. ESPN es otro feed, otro operador, otro equipo de humanos curando el score. Si los dos alguna vez no coinciden sobre un ganador, alguien está equivocado.
Leí la literatura de audits, decidí qué chequear y contra qué fuente. Claude escribió el script. Corrió hace unos días, el 15 de mayo, contra cada pick settleado que el sistema tenía en los libros hasta ese momento — 2.245 de ellos. Esto fue lo que volvió, textual del reporte.
Picks settleados totales: 2.245
PASARON (los 4 chequeos): 2.127 (94,7%)
Ganador equivocado: 0
Flag "won" equivocado: 0
Signo de profit equivocado: 0
Score string distinto: 100 (cosmético — ver abajo)
Juego no completado en ESPN: 18 (problema real — ver abajo)
Dos de esas filas son cero. Las dos que más importan.
Las 100 diferencias de score-string no son un problema de P&L. Dieciocho de ellas son simplemente campos NULL de picks muy tempranos donde el settler todavía no estaba escribiendo el string final del score — solo el resultado W/L. Las otras 82 son el residuo de un bug de timezone que mandé a mediados de abril: picks puestos tarde-UTC quedaron taggeados con la fecha de calendario equivocada, y el settler con fechas fuzzy que escribí después los matcheó al partido físico correcto pero guardó el score string del día anterior. Los ganadores y los profits están bien. El texto del score en la fila está stale. Higiene de data aburrida.
Los 18 picks "no completados" son el asterisco honesto. Son picks que el sistema settleó contra el resultado de un partido de reposición cuando el original había sido suspendido. La convención de los sportsbooks es anular las posiciones de partidos suspendidos y devolver la acción. Mi sistema los settleó igual. Impacto total de P&L si los reembolso: alrededor de ±$300, bastante abajo del 2% del portfolio. Plata real, error real. Vale la pena arreglarlo. En la lista.
Lo que el audit no encontró es la parte que más me importa. Ningún partido donde el equipo equivocado se llevó el flag de "won". Ninguna fila donde un P&L positivo debería haber sido negativo. Ninguna victoria inventada, ningún edge inflado, ninguna deriva silenciosa. Los números del gráfico de arriba son los mismos números que ESPN reporta sobre los mismos partidos.
El script del audit vive en el repo, tarda unos treinta segundos en correr, y escribe un JSON report fresco cada vez. Lo voy a wirearlo al pipeline del job diario esta semana, así cualquier divergencia futura levanta un flag el mismo día que aparece.
Lo que un audit como este realmente atrapa
Tres cosas para las que este tipo de cross-check está hecho, en orden creciente de cuánto me preocuparía si alguna vez se disparara.
La primera es un bug en el settle job dando vuelta ganadores en silencio. Un off-by-one en la fecha, un mapeo home/away equivocado, un glitch de timezone (el audit ya atrapó el residuo de uno de esos en la columna de score-string). Estos son mecánicos. No mienten. Solamente escriben la fila equivocada, y la fila equivocada se ve exactamente igual a cualquier otra fila.
La segunda es un registro fabricado por un modelo que alucina. Sistemas de IA inventando filas que se ven reales no es una preocupación teórica. Cualquiera que haya conectado un modelo a un pipeline lo vio confiadamente producir un registro que apunta a la nada. El script del audit no llama a ningún modelo en su loop — pero la filosofía es la misma. Cruzá lo que tu sistema afirma contra una fuente externa que no tiene incentivos para coincidir con ella.
La tercera es la que más importa: deriva silenciosa. El sistema empieza despacio a marcar resultados equivocados en algún rincón angosto de la data — un equipo específico, un día de la semana específico, un tipo de juego específico — y los números del titular igual se ven bien porque el resto de la data lo tapa. La deriva es la versión de este problema que no dispara una alerta y no aparece en un smoke test. La única manera de atraparla es comparar cada fila, regularmente, contra algo independiente.
Mantener a la IA honesta
El audit es una pieza de una disciplina más amplia que llegué a pensar como estructural para un sistema construido con IA: tenés que mantener a la IA honesta, y tenés que hacerlo más de una vez.
Un modelo puede alucinar un resultado la primera vez que le preguntás. Un modelo puede responder bien nueve veces seguidas y derivar en la décima. Un modelo puede estar perfectamente exacto hoy y degradarse en silencio después de un vendor update del que no te enteraste. La forma del fallo cambia. La disciplina de atraparlo no.
Dos prácticas que estoy incorporando a este proyecto como hábitos permanentes:
Chequeos contra fuentes externas, en un schedule. No solo al lanzamiento. No solo cuando algo se ve raro. En una cadencia regular, con thresholds, y con alguien (o algo) avisando cuando el resultado no coincide. El audit que acabo de describir va a quedar wireado al settle job diario esta semana, así cualquier divergencia futura entre mi sistema y ESPN levanta un flag el mismo día que aparece, no la próxima vez que yo me ponga a mirar.
Prompts diseñados para pelear contra la alucinación en la entrada. Las llamadas a Claude en este proyecto — la capa de síntesis de noticias detrás de los picks de los agentes, el strategy coach en la página de armado, las insight cards de IA en el dashboard — todas usan prompts que se apoyan fuerte contra la invención. Defaults conservadores. Schemas de output estructurado con campos obligatorios. Instrucciones explícitas de que "nada" es una respuesta válida cuando la evidencia es fina. La capa de síntesis (el Post 3 fue mayormente sobre eso) está armada para que el modelo solamente pueda reducir o bloquear una llamada — no puede inventarla. Decir nada en la mayoría de los partidos es una feature, no un fallo.
Ninguna de las dos es una cura. Las dos son el tipo de disciplina permanente que ahora trato como parte de mandar a producción cualquier cosa que use un modelo en el loop. La línea de fondo de toda esta serie — el Co-Authored-By en el git log, las pruebas del Post 2, este audit, los prompts conservadores — es una sola cosa continua. La confianza no se declara. Se construye, pieza por pieza, con chequeos a cada lado de la IA.
El lado de compliance de la misma semana
También estuve trabajando en la superficie de compliance del lado de consumo del producto. Ese trabajo pasó mayormente en abril, pero algunos ítems tuvieron su cleanup final esta semana.
La versión corta, porque no debería ser más que la versión corta en este post:
- Disclosures de FTC click-to-cancel, un cron de Vercel que manda recordatorios pre-renovación, y un botón de "Manage Subscription" que va directo al customer portal de Stripe.
- Una disclosure del Artículo 50 del EU AI Act en cada página donde un usuario le habla al modelo: "You are chatting with an AI, not a human."
- Una política de privacidad ampliada de solo-California para cubrir el resto de las leyes estatales de privacidad de EE.UU. en los libros, más un middleware
Sec-GPCque auto-honora el header de Global Privacy Control como una señal de opt-out. - Borrado de cuenta que cascadea, portabilidad de datos que devuelve cada fila sobre un usuario, una casilla de consentimiento de 18+ en el signup, y un link de juego responsable en el footer porque la adyacencia importa incluso en un producto sin plata.
El punto más grande sobre el trabajo de compliance es el mismo que sobre el trabajo de audit: es plomería más que política. El modelo lee las reglas y escribe el código. Yo leo las reglas y decido lo que el código tiene que hacer. La línea entre los dos no se movió.
La semana que viene
El Post 6 se corre al producto en sí: las decisiones de UX que cambiaron lo que los agentes le parecen a un usuario, el framing del coach, el cuidado con el lenguaje del producto, y el puñado chico de decisiones de diseño que hicieron la diferencia entre "proyecto de ingeniería" y "producto real."
Anteriormente en esta serie: Semana 1 — la génesis · Semana 2 — el pivot (las pruebas) · Semana 3 — la data stack · Semana 4 — lo que realmente quiere decir "lo construí con IA".
Estas son notas personales de un side project que hago en mi tiempo libre con mis propios recursos. Las opiniones acá son mías y no están conectadas, ni endosadas, ni representan a mi empleador ni a ninguna parte de mi trabajo profesional.



