How I keep my AI honest.
Week 5 of a 10-week build-in-public series. A six-week portfolio update, an independent audit, and a short note on the compliance side of the same week.


Post 4 was about who did what on this project. This week is about whether what got done is actually working, and checking that the numbers I've been posting since Week 3 are the real numbers.
The short version: yes. With one honest asterisk I'll get to.
Five weeks in
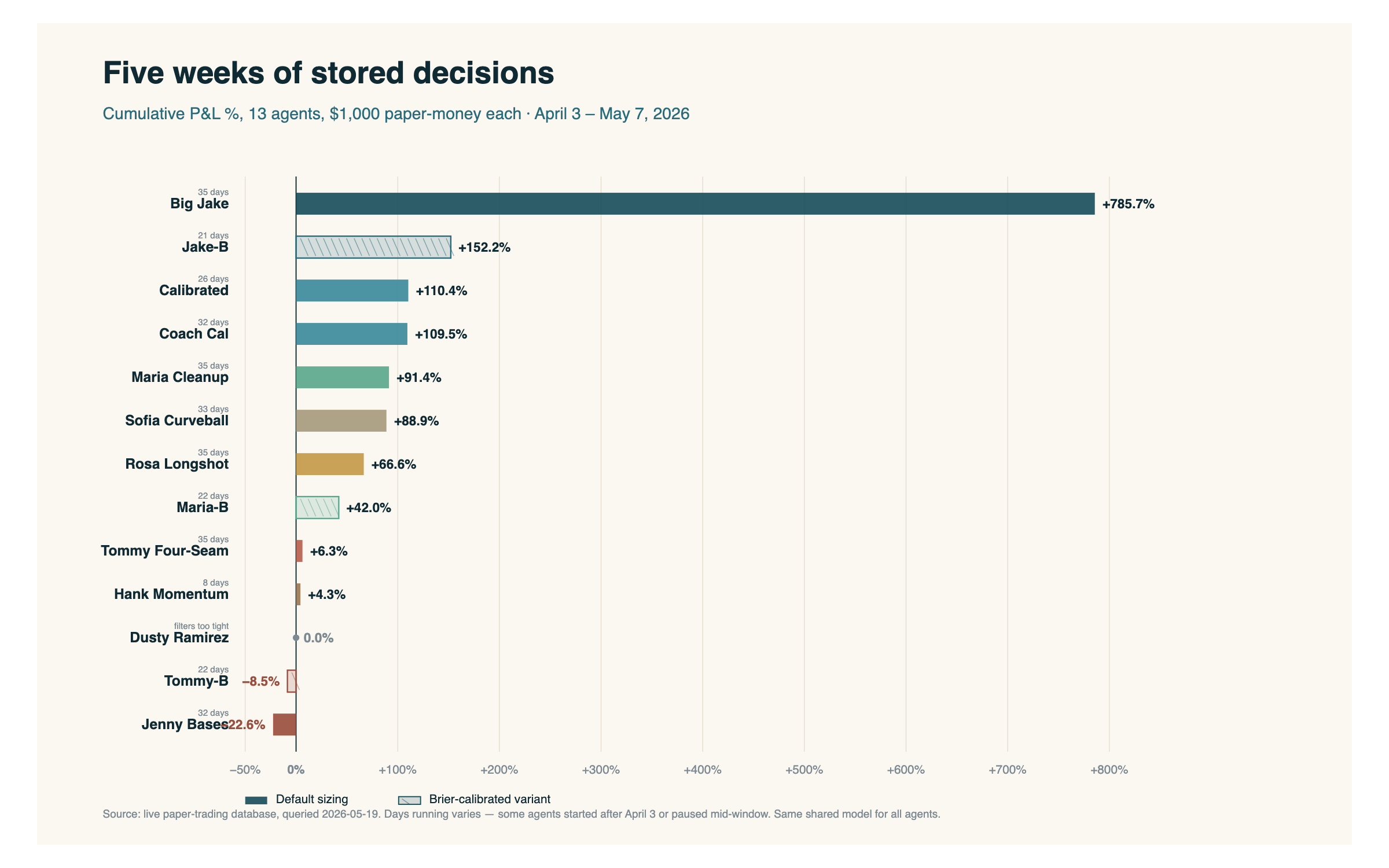
Thirteen agents on the chart this week — one more row than Post 4. Dusty Ramirez was on the roster then too, just with zero picks to draw. I'll get to him. Same shared model behind all of them. Different sizing and selection rules. Five weeks of paper-trading in the books.
A few observations.
The portfolio as a whole is up +$14,261 on $12,000 deployed over 35 days — roughly +119%. Across all thirteen agents, the system has settled 1,801 picks and skipped 24,307. That is about thirteen and a half skips for every pick.
Big Jake widened his lead to +786%. On a $1,000 starting bankroll that is $7,860 of paper-money, on a shared model with the same underlying inputs as everyone else. The story there is sizing, not selection. He takes a bigger position when he sees an edge. Everyone else does not.
The Brier variants matured. Jake-B has now had enough days to sit second on the board (+152%), which is the kind of result calibration-tuned probabilities are supposed to produce on a longer sample. Both Tommy variants are still struggling. Tommy-B is the only Brier agent in the red.
Some agents are settling into the middle of the table. Maria Cleanup, Sofia Curveball, and Rosa Longshot all moved around between Week 4 and Week 5 — small samples are noisy and the regression is real.
Dusty Ramirez is the new row on the board, and the new asterisk: he has placed zero picks in six weeks. His filter thresholds are so tight that nothing on the slate qualifies. That is a real bug, not a strategy. Fix on the list.
Jenny Bases was deactivated on May 7 after sliding to −22.6%. Worth saying out loud: the negative numbers are real too. The system isn't curated. Every agent that started kept running until I had a reason to stop one.
The sanity check I built this week
Somewhere around day forty, I caught myself second-guessing my own numbers.
The math was fine. The arithmetic was fine. The portfolio chart you just saw was fine. But these numbers all come from a system I built. The agents are mine. The model behind them is mine. The settle job that decides who won each game and writes the profit row is mine. The dashboard I was reading my own results from is mine. Four "mines" in a row, and I was about to keep posting them, week after week, as if they were facts.
That was the moment I decided I needed an outside check.
If you've followed the series, you know the agents settle their picks through a job that calls the MLB Stats API for final scores. That settle job decides who won, fills in the profit, and writes the row. The model. The settler. The story. All inside one process, on one database, that I own.
So this week I built a separate module that audits everything from the outside. It runs read-only. It pulls every settled pick from the database, asks ESPN's public MLB scoreboard what they say about that game, and compares four things:
- Did the score match?
- Did the winner match?
- Was the game actually played to completion?
- Given the score, is our "won" flag — the field that determines whether the pick paid out — correct?
ESPN matters here because it is genuinely independent of my pipeline. The internal source is MLB Stats API. If I cross-checked against that, I would be asking the same source twice and calling the answer confirmation. ESPN is a different feed, a different operator, a different team of humans curating the score. If the two ever disagree on a winner, somebody is wrong.
I read the audit literature, decided what to check and against which source. Claude wrote the script. It ran a few days ago, on May 15, against every settled pick the system had on the books to that point — 2,245 of them. Here is what came back, verbatim from the report.
Total settled picks: 2,245
PASSED (all four checks): 2,127 (94.7%)
Wrong winner: 0
Wrong "won" flag: 0
Wrong profit sign: 0
Score string mismatch: 100 (cosmetic — see below)
Game not completed in ESPN: 18 (real issue — see below)
Two of those rows are zero. The two that matter most.
The score-string mismatches (100 picks) are not a P&L problem. Eighteen of them are simply NULL fields from very early picks where the settler wasn't writing the final score string yet — only the W/L outcome. The other 82 are the residue of a timezone bug I shipped in mid-April: picks placed late-UTC were tagged with the wrong calendar date, and the fuzzy-date settler I wrote afterward matched them to the right physical game but stored the previous day's score string. Winners and profits are correct. The score text on the row is stale. Boring data hygiene.
The 18 "not completed" picks are the honest asterisk. These are picks the system settled against a makeup game's outcome when the original game was postponed. Sportsbook convention is to void postponed-game positions and return the action. My system settled them anyway. Total P&L impact if I refund them: around ±$300, well under 2% of the portfolio. Real money, real mistake. Worth fixing. On the list.
What the audit did not find is the part I care about most. No game where the wrong team got the "won" flag. No row where a positive P&L should have been negative. No fabricated win, no inflated edge, no quiet drift. The numbers in the chart above are the same numbers ESPN reports about the same games.
The audit script lives in the repo, takes about thirty seconds to run, and writes a fresh JSON report each time. I'll wire it into the daily job pipeline this week so any future divergence trips an alert the same day it appears.
What an audit like this actually catches
Three things this kind of cross-check is built for, in increasing order of how much it would worry me if it ever fired.
The first is a settle-job bug silently flipping winners. A single off-by-one date, a wrong home/away mapping, a timezone glitch (the audit caught the residue of one of those in the score-string column already). These are mechanical. They don't lie. They just write the wrong row, and the wrong row looks exactly like every other row.
The second is a fabricated record from a model that hallucinates. AI systems inventing rows that look real isn't a theoretical concern. Anyone who has wired a model into a pipeline has watched it confidently produce a record that points at nothing. The audit script doesn't actually call a model anywhere in its loop — but the philosophy is the same. Cross-check what your system claims against an outside source that has no incentive to agree with it.
The third is the one that matters most: silent drift. The system slowly starts marking the wrong outcomes in some narrow corner of the data — a specific team, a specific day of the week, a specific game type — and the headline numbers still look fine because the rest of the data drowns it out. Drift is the version of this problem that doesn't trip an alert and doesn't show up in a smoke test. The only way to catch it is to compare every row, regularly, against something independent.
Keeping AI honest
The audit is one piece of a broader discipline I have come to think of as load-bearing for an AI-built system: you have to keep the AI honest, and you have to do it more than once.
A model can hallucinate a result the first time you ask it. A model can answer correctly nine times in a row and then drift on the tenth. A model can be perfectly accurate today and then quietly degrade after a vendor update you didn't know happened. The shape of the failure changes. The discipline of catching it doesn't.
Two practices I am building into this project as standing habits:
Outside-source checks, on a schedule. Not just at launch. Not just when something looks off. On a regular cadence, with thresholds, and with someone (or something) paged when the result doesn't match. The audit I just described is going to be wired into the daily settle job this week, so any future divergence between my system and ESPN trips a flag the same day it appears, not the next time I happen to look.
Prompts engineered to fight hallucination on the way in. The Claude calls on this project — the news synthesis layer behind the agents' picks, the strategy coach on the build page, the AI insight cards on the dashboard — all use prompts that lean hard against invention. Conservative defaults. Structured-output schemas with required fields. Explicit instructions that "nothing" is a valid answer when the evidence is thin. The synthesis layer (Post 3 was largely about it) is set up so the model can only reduce or block a call — it cannot invent one. Saying nothing on most games is a feature, not a failure.
Neither of those is a cure. Both are the kind of standing discipline I now treat as part of shipping anything that uses a model in the loop. The honest-accounting through-line of this whole series — the Co-Authored-By in the git log, the receipts in Post 2, this audit, the conservative prompts — is one continuous thing. Trust does not get declared. It gets built, piece by piece, with checks on each side of the AI.
The compliance side of the same week
I had also been working through the compliance surface for the consumer side of the product. That work happened mostly in April, but a few items got their final cleanup this week.
The short version, because it shouldn't be more than the short version on this post:
- FTC click-to-cancel disclosures, a Vercel cron that sends pre-renewal reminders, and a "Manage Subscription" button that goes directly to the Stripe customer portal.
- An EU AI Act Article 50 disclosure on every page where a user talks to the model: "You are chatting with an AI, not a human."
- A privacy policy broadened from California-only to cover the rest of the US state privacy laws on the books, plus a
Sec-GPCmiddleware that auto-honors the Global Privacy Control header as an opt-out signal. - Account deletion that cascades, data portability that returns every row about a user, an 18+ consent checkbox at signup, and a responsible-gaming link in the footer because the adjacency matters even on a no-money product.
The bigger point about the compliance work is the same as the audit work: it is plumbing more than it is policy. The model reads the rules and writes the code. I read the rules and decide what the code has to do. The line between us has not moved.
Next week
Post 6 shifts to the product itself: the UX decisions that changed what the agents look like to a user, the coach framing, the careful product language, and the small handful of design calls that made the difference between "engineering project" and "real product."
If you've built something with money on the line — real or paper — and you've drawn the line for your own sanity checks somewhere different than I did, I'd like to hear it.
Previously in this series: Week 1 — the genesis · Week 2 — the pivot (the receipts) · Week 3 — the data stack · Week 4 — what "I built it with AI" actually means.
These are personal notes from a side project I do on my own time with my own resources. The views here are mine and are not connected to, endorsed by, or representative of my employer or any of my professional work.



