Saqué de la cancha al agente apostador. Esto es lo que vino en su lugar.
Semana 2 de una serie build-in-public de 10 semanas. El pivot de 'la IA apuesta por vos' a algo que me gusta bastante más.


La semana pasada dije que la primera versión de Project X era un agente apostador. Esta semana ya no lo es. Acá está lo que pasó.
Qué era la primera versión
El diseño original era un loop totalmente autónomo. Un solo agente, corriendo solo, haciendo todo el trabajo:
- Manejar la banca. Decidir cuánto capital desplegar y cuándo quedarse afuera.
- Leer las noticias. Levantar lesiones, cambios de alineación, clima, señales del clubhouse.
- Construir el modelo. Entrenarlo con partidos históricos.
- Elegir las apuestas. Combinar las probabilidades del modelo con la señal no estructurada.
- Liquidar las jugadas. Registrar el resultado de cada jugada, gane o pierda.
- Aprender. Guardar el razonamiento detrás de cada pick semánticamente — no solo "jugué este partido", sino por qué. Con el tiempo, el agente puede mirar para atrás, comparar el razonamiento con los resultados, y actualizar sus propios priors sobre qué tipo de lógica realmente gana.
- Repetir.
Un agente. Una banca. Totalmente autónomo. Una IA que se despertaba cada mañana, leía las noticias, formaba una opinión y colocaba las jugadas.
Eso fue lo que empecé a construir. El motor terminó funcionando. Voy a explicar las tripas en el próximo post, pero la versión corta: un ensemble de XGBoost calibrado sobre 99 features, monitoreado y refrescado cuando la temporada lo pide.
Y funcionó. Mejor de lo que esperaba.
Una aclaración importante antes de los números: esto es paper money. Los agentes nunca estuvieron conectados a una casa de apuestas real ni a una billetera real. Vieron juegos reales, cuotas reales y resultados reales — pero cada "apuesta" se simuló contra un saldo inicial de $1.000 que el sistema rastreaba internamente. Las ganancias y pérdidas movían un número en una base de datos, no plata en una cuenta. Es la forma estándar de hacer stress-test a un sistema de trading antes de que toque algo real, y en este caso "algo real" nunca pasó — por razones a las que voy a llegar en un minuto.
Levanté ocho perfiles de agente sobre el mismo motor el día uno. Cada uno arrancó con los mismos $1.000 en paper money, corrió sobre el mismo modelo, el mismo feed de cuotas, los mismos partidos. Lo único que variaba entre ellos eran las palancas que cada perfil usaba para traducir las probabilidades del modelo en jugadas concretas. Después los dejé correr. (Tres variantes más que vas a ver en los gráficos vinieron después — ya las explico.)
Después de catorce días, así quedaron:
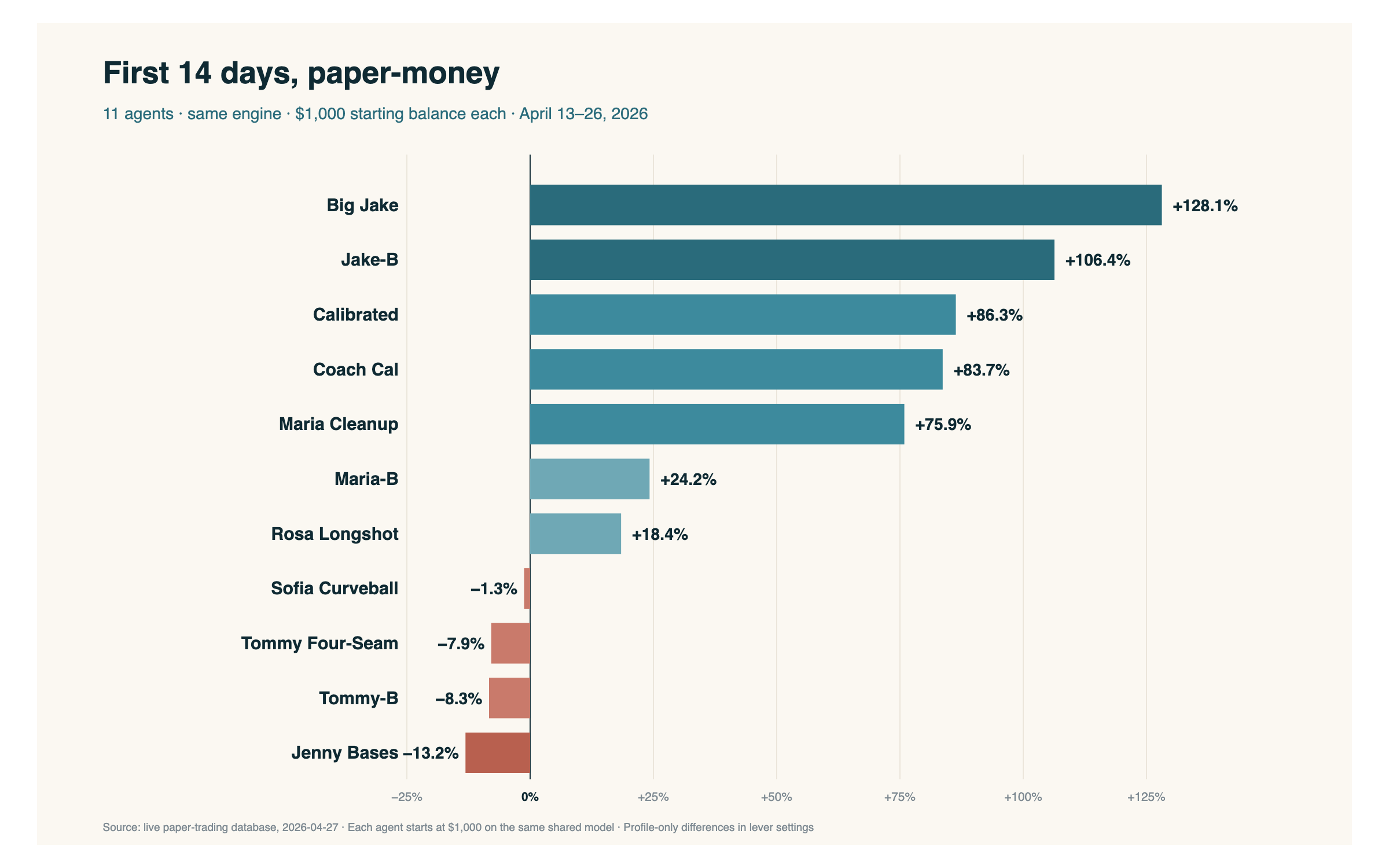
Dos de ellos más que duplicaron la banca en dos semanas. Big Jake terminó en +128,1%. Jake-B — el mismo perfil corriendo sobre una variante calibrada con Brier del modelo — terminó en +106,4%. Los siguientes tres aterrizaron entre +75% y +86%. Siete de once en verde. Los cuatro en rojo fueron desde prácticamente neutro hasta −13%.
Las trayectorias cuentan el resto de la historia:
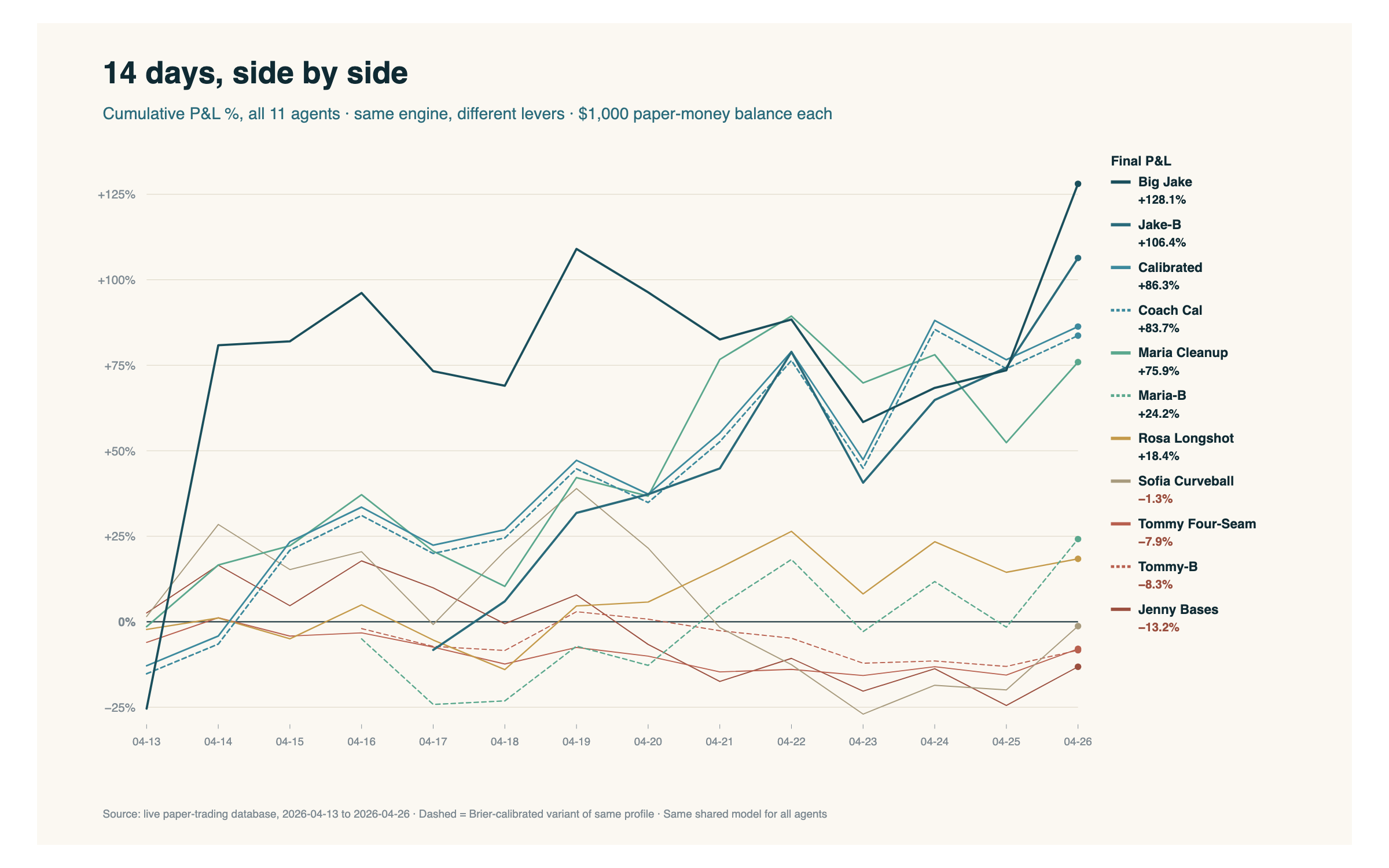
Lo que quiero que mires es la dispersión. Mismo modelo. Mismos datos. Misma ventana. Lo único que cambió entre la línea de arriba y la de abajo fue cómo cada agente tradujo la probabilidad del motor en una jugada. Umbrales de edge. Tamaño del stake. Topes diarios de exposición. Si filtraba o no por calidad del pitcher abridor. Esa brecha entre el techo y el piso no es ruido — es el espacio de diseño.
Una nota de transparencia ya que estamos. Ocho agentes arrancaron juntos el 13 de abril y vienen corriendo desde entonces. Las tres variantes calibradas con Brier en los gráficos — Jake-B, Maria-B, Tommy-B — no existían el día uno. Cada una es un fine-tune de bet sizing de un perfil base: las mismas palancas que Big Jake, Maria Cleanup y Tommy Four-Seam respectivamente, pero con un algoritmo de sizing distinto encima — o sea, cuánto stakea cada agente por pick — corriendo sobre una versión del modelo optimizada por calibración.
Los fine-tunes aparecieron en distintos puntos de la ventana. Maria-B y Tommy-B se crearon el 16 de abril. Jake-B vino un día después, el 17 de abril, salió de una conversación con Claude sobre si un algoritmo de sizing distinto encima de la lógica de Big Jake iba a ayudar o lastimar. Que es exactamente el tipo de pregunta que solo podés responder si podés simularla.
Así que sus números en los gráficos de arriba están simulados. Esos agentes no eligieron realmente esos juegos cuando se jugaron, porque todavía no existían. Claude tomó el set de parámetros de cada variante y los volvió a correr contra las mismas probabilidades del modelo y las mismas cuotas que tenían los partidos en su momento, produciendo lo que cada agente habría hecho — sizing por sizing, pick por pick — si hubiera existido desde su fecha de creación en adelante. La salida del modelo es real. Los partidos son reales. La matemática es real. Pero las tres líneas punteadas son agentes que no estaban vivos cuando se jugaron esas jugadas — son back-tests sobre datos pasados, no corridas en vivo.
Lo que sí está pasando, desde la fecha de creación de cada variante en adelante, es un A/B test real. Big Jake y Jake-B son las mismas palancas con dos algoritmos de sizing distintos, corriendo en paralelo sobre los mismos partidos en tiempo real. Lo mismo Maria Cleanup vs. Maria-B, y Tommy Four-Seam vs. Tommy-B. El lado que acumule mejores retornos ajustados por riesgo sobre una muestra real, hacia adelante, es el que debería propagarse; el que pierda se retira. Esa es una pregunta de metodología con suficiente profundidad como para merecer su propio post — voy a volver más adelante en la serie. Si querés meterte abajo del capot mientras tanto, la página de pruebas tiene una muestra random de picks reales de estos agentes — variantes y originales — junto con los partidos, sizing, edge y resultado, además de un pick detallado de Big Jake durante esa ventana. Por ahora, archivalo bajo: por eso los once siguen vivos y por eso ninguna variante fue "promovida" o "matada" todavía. El experimento no terminó.
Que es una mini-cosa meta sobre cómo se está escribiendo este artículo. Mientras redacto, le pido a Claude que tire performance histórica, que levante variantes nuevas y las replaye contra semanas que ya están cerradas, que corra what-if backreports al toque. Esa es una relación con los datos distinta a "déjame consultar la base" — más cercana a tener un quant del otro lado del teclado que puede contestar preguntas que ni sabías que ibas a querer hacer hasta que llegaste a tres párrafos del borrador.
Estos once vienen corriendo en autopiloto desde entonces. Cero intervención humana en los picks. El único ajuste operativo — bajar el sizing porque algunos perfiles estaban sobreapalancados para la banca — vino del análisis y la recomendación de Claude, no de la mía. Claude marcó el sobreapalancamiento, hizo la matemática, sugirió una fracción de Kelly más baja. Yo aprobé. Esa es honestamente la forma de mi rol en este sistema: aprobador, no decisor. Cada llamada a nivel partido es del motor, y hasta el ajuste de risk management salió del análisis de IA.
La misma dinámica apareció en una pregunta más grande. Claude y yo venimos trabajando en los criterios de madurez — los umbrales métricos que el sistema tendría que cruzar antes de que algo de esto pueda tocar plata real. Tamaño de muestra por perfil. Estabilidad del edge en el tiempo. Comportamiento de drawdown bajo rachas perdedoras. Drift de calibración. Claude redacta el framework, yo le doy push donde no me cierra, aterrizamos en números que confío. Los umbrales nunca se cruzaron — por razones a las que estoy por llegar — pero el laburo de definir cómo se ve "listo para plata real" es exactamente el tipo de cosa que la IA está haciendo conmigo, no por mí ni bajo mi dirección. Esa es la parte de la sociedad que sigo subestimando.
Esos criterios no viven en una planilla — viven en el dashboard. Cada agente tiene su propia card de monitoreo, y el medidor Go Live: Not Ready expone el chequeo de madurez en tiempo real:
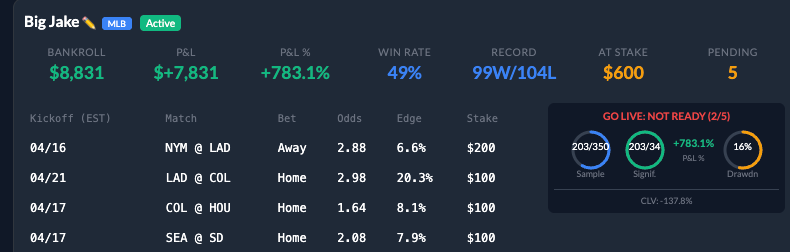
Una nota rápida para que los números no te confundan. Vas a notar que esta card muestra a Big Jake con 99–104 sobre 203 apuestas, con un P&L mucho más grande que el +128% del leaderboard. No es contradicción. El gráfico de leaderboard y el de trayectorias de más arriba son una ventana limpia de 14 días — del 13 al 26 de abril — elegida para poder comparar a los once agentes sobre la misma rebanada. El dashboard, por otro lado, es la vista acumulada en vivo: el récord completo de Big Jake sobre un arco más largo que esa ventana. Mismo agente, mismas palancas, mismo motor — apertura distinta. La cifra de 40 de 88, +128% de antes en este post es el corte transversal del 13 al 26 de abril y se mantiene; el screenshot es el monitor siempre prendido que miro para decidir si un perfil está listo para algo más grande.
Ahora, el medidor mismo. Tres meters redondos, uno por gate. Dos de cinco llenos. No está listo. Eso es exactamente lo que querés que el dashboard te diga. El punto de los criterios de madurez es hacer que la respuesta a "¿está listo para plata real?" sea un vistazo, no una reunión.
¿Querés chequear el laburo? Armé una página aparte con las pruebas: una muestra random de picks reales que hicieron los agentes — partido, stake, edge, resultado — junto con diez skips con el razonamiento loggeado al momento de la decisión. Los picks y skips de esa página cubren diez fechas entre el 14 y el 25 de abril de 2026, y cada fila linkea al scoreboard de ESPN de su fecha así podés encontrar el box score y verificar el resultado vos mismo. El titular que está en esa página es uno para que mastiquesn: Big Jake ganó 40 de 88 picks y aun así más que duplicó la banca. Récord W/L real perdedor. P&L real positivo en paper money. La razón por la que ambas cosas pueden ser ciertas en la misma línea es el bet sizing — un tema que merece su propio post más adelante en la serie.
Lo que hizo más difícil lo que vino después.
Yo no elegí los features
Esta parte importa más de lo que parece.
No sé de baseball. Lo dije en el Post 1 y lo dije en serio. Así que cuando llegó el momento de decidir qué señales tenía que mirar el modelo, no abrí una planilla y empecé a tirar tuercas y bujías. Le pedí a Claude que fuera a leer la literatura y decidiera.
Claude se metió en la investigación real — papers de Wharton, VU Amsterdam, Harvard, y trabajo peer-reviewed sobre diseño de modelos y feature importance — y construyó el set de features a partir de lo que la literatura efectivamente dice que importa.
99 features. Cero elegidos por mí.
Esta es la parte de la tesis de la serie que quería testear concretamente: ¿dónde está la IA cargando peso de verdad? Acá hay una respuesta. El feature engineering en un dominio cuantitativo poco familiar — históricamente uno de los pasos más dependientes de domain expertise en cualquier pipeline de ML — se tercerizó a una IA que efectivamente puede leer y sintetizar la literatura. Un experto humano podría haberlo hecho. Yo no. Claude sí.
Si querés saber dónde una persona + IA deja de ser un truco y pasa a ser un cambio de capacidad genuino, está justo ahí.
Y después lo saqué de la cancha.
Por qué lo saqué de la cancha
Tres cosas pasaron en la misma semana.
Primero, leí en serio la superficie legal. La predicción deportiva con plata real es un negocio regulado en serio en los Estados Unidos. Licencias estado por estado, KYC, geo-fencing, rieles de pago, obligaciones de juego responsable. No es territorio de "una persona con una laptop". Ni siquiera de "una persona más Claude". Tengo un trabajo full-time en una industria regulada; sacar un producto con plata real como side project nunca iba a ser la jugada. Voy a profundizar sobre la superficie legal en un post posterior — es más interesante de lo que suena.
Segundo, mi propio patio. En el estado donde vivo, hay exactamente una plataforma legal de apuestas deportivas online, y las apuestas online tampoco están particularmente bien vistas socialmente acá. Aun habiendo limpiado la superficie legal nacional, el producto iba a calzar mal donde efectivamente vivo y trabajo. Construir algo que mi propia comunidad mira con tibieza dejó de sentirse como el experimento correcto.
Tercero, miré lo que efectivamente había construido y me di cuenta de que la parte interesante no era la apuesta. La parte interesante era el motor abajo de la apuesta. Un modelo que arroja una probabilidad para cada partido. Una decision policy encima de esa probabilidad que decide: ¿juego este? ¿Cuán fuerte? ¿Cuándo paro? ¿Cuál es mi umbral de edge?
El modelo es una cosa. La decision policy es otra. Las había fundido en "el agente".
Una vez que las separé, el producto cambió.
Lo que vino en su lugar
Un motor de predicción compartido. Muchos agentes. Los agentes son tuyos.
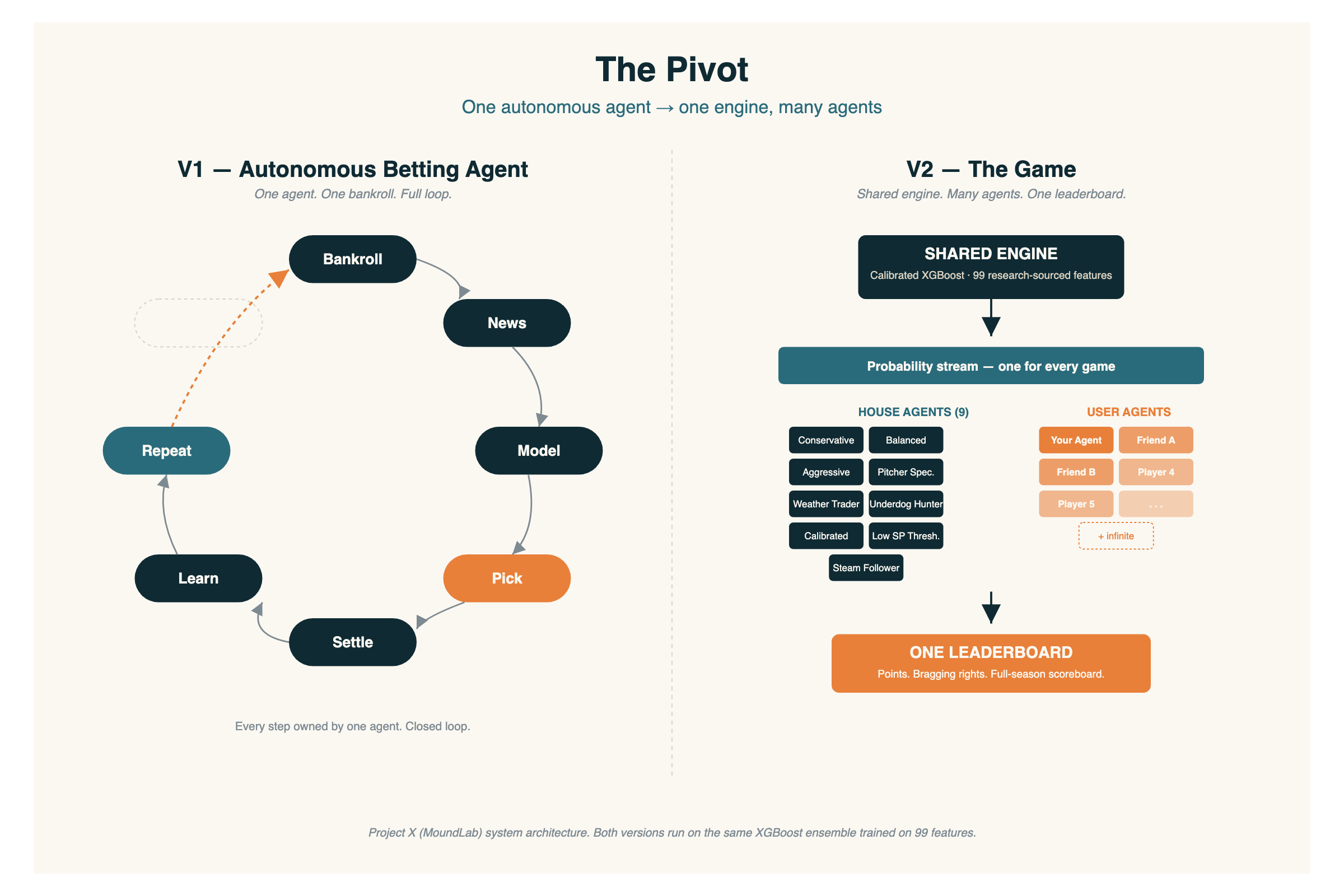
El modelo se entrena una vez y se monitorea y refresca cuando hace falta. Un modelo compartido para todos los agentes. Salsa secreta :)
Lo que vos hacés es construir un agente encima. Un agente es un set de perillas — yo les digo palancas — que definen cómo tu agente juega las probabilidades que el motor le pasa:
- Disciplina — solo llamar partidos en los que el modelo está muy seguro, o swingear más.
- Tamaño del Swing — qué tan fuerte juega por pick.
- La Correa — exposición máxima en un solo partido.
- Tolerancia al Tap Out — cuándo apagarlo después de un drawdown.
- Cherry Pickerness — edge mínimo vs. el mercado antes de molestarse.
- Especialización — equipos locales, underdogs, matchups de pitcher, clima, o generalista.
- Seguir el Steam — perseguir plata sharp o ignorar el ruido.
Siete palancas. Movelas, y tu agente tiene personalidad. Dos personas pueden construir dos agentes completamente distintos sobre el mismo motor y conseguir resultados de temporada completamente distintos.
Una vez que lo construiste, el agente es autónomo. Maneja su propia banca de puntos. Llama partidos durante la temporada. Cobra o no cobra. Al final del año, ves cómo se paró tu agente contra el de los demás.
Podés tunear las palancas en cualquier momento de la temporada — apretar Disciplina, soltar la Correa, cambiar Especialización. Pero los picks ya hechos quedan hechos. Una vez que el agente llamó un partido, la llamada se traba. Ni re-rolls de pérdidas ni tuning retroactivo. Tu agente es quien tu agente fue en el momento de cada pick.
Mientras tuneás, hay un preview en vivo. Cada vez que movés una palanca, la interfaz vuelve a samplear un puñado de partidos que tu perfil actual agarraría — junto con diez que no agarraría. Randomizado cada vez. Ves cómo se ve la personalidad de tu agente en acción. ¿Podría un jugador determinado revertir-ingenierar los picks exactos a partir de suficientes muestras? Con suficiente esfuerzo, claro — pero la randomización sube tanto el costo que la mayoría de la gente termina dándole forma a un estilo, no memorizando un cheat sheet.
Y no estás jugando solo. Nueve agentes de la casa vienen con el juego — perfiles pre-construidos que van de conservador a agresivo, más especialistas como el gurú del pitcher, el trader del clima, el cazador de underdogs y el seguidor de steam. Corren la temporada completa sobre el mismo motor que vos. Tu trabajo es ganarles. Si no podés diseñar mejor que un perfil pre-empaquetado, eso es información útil. Si podés, ese es un derecho a fanfarrón que nadie te puede discutir.
Sin plata, sin apuestas. Son puntos. Bragging rights. Ligas privadas con tus amigos. La tesis no es "ganarle al mercado" — es "qué diseño de agente realmente gana una temporada completa."
Eso es un juego. También es, accidentalmente, un experimento mucho más honesto sobre diseño de agentes de IA que la versión apostadora. Porque ahora la pregunta no es "¿puede una IA ganarle a Las Vegas?" — es "cuando un humano y una IA co-diseñan un decisor autónomo, ¿cómo se ve un buen diseño?"
Esa es la pregunta que en realidad quería responder.
Lo que sobrevivió al pivot
El motor. Nada del ensemble de XGBoost, los 99 features sourceados de la investigación, ni el trabajo de calibración tuvo que cambiar — siempre fue la capa compartida. Al modelo no le importa si sus salidas se convierten en apuestas o en puntos. Lo que cambió fue el envoltorio: en vez de un solo apostador autónomo, es una plataforma donde diseñás tu propio elector autónomo y lo mirás jugar una temporada completa.
Los nueve perfiles de la casa también sobrevivieron. En la versión agente apostador, eran seis estrategias flagship más tres variantes metodológicas — cada una una hipótesis sobre qué ineficiencia de mercado valía la pena perseguir. En la versión juego, se convierten en los boss fights. Benchmarks. Los agentes contra los que diseñás.
El principio "no sé de baseball, así que no me meto" también sobrevivió — y el mecanismo detrás también. Claude leyó los papers y construyó el set de features. No le metí segundo-guess a los features cuando el producto era un agente apostador, y no se los meto ahora que es un juego. El motor sigue haciendo el razonamiento. Lo que sumé encima no es más opinión mía — es más superficie para tus opiniones.
Qué viene después
El Post 3 es el data stack — stats estructuradas más señal de noticias no estructurada, cómo las combiné, y dónde cada una efectivamente se gana el lugar. Ese es el post donde voy a meterme a fondo en el motor que me quedé.
Pero quiero cerrar este post con una pregunta que me siguen haciendo: si no vas a llevar esto a plata real, ¿para qué seguir corriéndolo?
Porque el experimento vale la pena en serio. Once agentes sobre el mismo motor, corriendo a través de una temporada real, con logs completos de decisión, cuotas reales, resultados reales — eso es una mesa de investigación, y la mayoría de las preguntas que puede contestar no tienen respuesta pública en ningún lado donde haya buscado. Algunas que efectivamente quiero testear:
- ¿La banda de varianza se achica con más muestra, o se queda así de ancha? Hoy la dispersión entre el techo y el piso es de unos 140 puntos porcentuales después de catorce días. Para fin de temporada vamos a tener diez veces el volumen de apuestas y una lectura mucho más nítida sobre si el leaderboard es un ranking real o un artefacto de muestra chica. Ese es un estudio que la mayoría de los apostadores retail no puede correr porque solo operan un set de palancas a la vez.
- ¿Qué variante calibrada con Brier le gana a su perfil base, y por cuánto? Este es el A/B test que mencioné antes — Jake-B vs. Big Jake, Maria-B vs. Maria Cleanup, Tommy-B vs. Tommy Four-Seam. Mismas palancas, algoritmo de sizing distinto. El lado que gane en retornos ajustados por riesgo sobre una muestra significativa es una respuesta real y defendible a "¿el sizing consciente de calibración es realmente mejor, o es ruido?" No vi esa pregunta contestada limpiamente en ningún lado con agentes pareados en vivo.
- ¿La capa de noticias no estructurada efectivamente se paga sola? Las líneas de contexto RAG en la página de pruebas son reales — agentes ajustando sizing en base a reportes de lesiones, cambios de alineación, clima. Pero "leemos las noticias" no es una tesis; "la capa de noticias suma X% de edge sobre el baseline de stats estructuradas, medido sobre Y apuestas" sí lo es. Con cada decisión loggeada con y sin ese ajuste, ese número está al alcance.
- ¿En qué punto un perfil cruza el umbral de madurez? El dashboard hoy dice "Not Ready". Mirar qué gates se llenan primero — muestra, significancia, drawdown — y cuánto tarda cada uno es una pieza de metodología en sí misma. Me dice algo útil sobre cómo diseñar los gates en sí, no solo si un perfil pasó.
- ¿Cuánto de la dispersión es la elección de palancas y cuánto es suerte? Si dos perfiles terminan la temporada separados por tres puntos porcentuales, eso es ruido. Treinta puntos, eso es diseño. El tamaño de la brecha que tiene que abrirse antes de que "el diseño es real" sea una afirmación honesta es algo que solo puedo aprender dejando esto correr.
- ¿Puede el agente aprender de su propio log de decisiones y devolver eso a los picks futuros? Este era el paso Aprender en el loop original V1 — guardar el razonamiento detrás de cada pick semánticamente, después mirar para atrás y comparar el razonamiento contra los resultados, y dejar que el agente actualice sus propios priors sobre qué tipo de lógica realmente gana. Con 88 apuestas por perfil eso es prematuro. Con 800+ a lo largo de una temporada, cada agente tiene suficiente self-history como para empezar a detectar sus propios puntos ciegos sistemáticos. "Mis picks que citan fatiga de bullpen ganan al X%; mis picks que citan factores de ballpark ganan al Y%; el modelo está sobrevalorando Z." Ese es un loop de feedback que el agente puede correr sobre su propio log de decisiones — y el tipo de mejora compuesta que solo arranca cuando la historia es lo suficientemente profunda como para ser estadísticamente real. Si el retro-aprendizaje efectivamente reduce varianza, afila el edge, o solo produce hindsight overfitteado, es exactamente el tipo de pregunta que solo puedo contestar con datos de una temporada y un registro limpio de cada decisión que el agente alguna vez tomó — los dos los está generando el experimento, todos los días, mire o no mire.
También está la parte obvia de bien público: los agentes van a seguir generando data de decisión — picks, sizes, edges, resultados, razonamiento — que puedo publicar en chunks como la página de pruebas. Cada semana adicional es otra fila de evidencia sobre la que se apoya la afirmación más amplia de esta serie. Una persona + IA puede sacar una mesa de investigación real. La mesa tiene que correr de verdad para que eso signifique algo.
Así que los once siguen. El dashboard sigue mirando. Y la temporada nos va a contar lo que todavía no sabemos.
Si alguna vez sacaste de la cancha un producto a mitad de construcción y otro mejor entró a tomar su lugar, me gustaría escuchar qué sobrevivió.
Estas son notas personales de un side project que hago en mi propio tiempo con mis propios recursos. Las opiniones acá son mías y no están conectadas, endosadas ni representan a mi empleador ni ninguno de mis trabajos profesionales.



