What "I built it with AI" actually means.
Week 4 of a 10-week build-in-public series. What working with Claude Code as my engineering team actually looks like — what it does, what I do, and how the line keeps moving.


Last week I said the RAG synthesis layer was one moment where Claude Code carried real weight. That was true, but it was a small part of the truth. Claude carries real weight on a lot of this project. It also doesn't carry a lot, and the line between the two keeps moving. This post is about what working in that mode actually looks like for me, day to day.
Four weeks in
Before getting into any of that, here's where the agents stand after four weeks of paper-trading. Same 12 agents from last week. Same shared model behind all of them. Different sizing and selection rules. One more week of decisions on top of what I showed in Post 3.
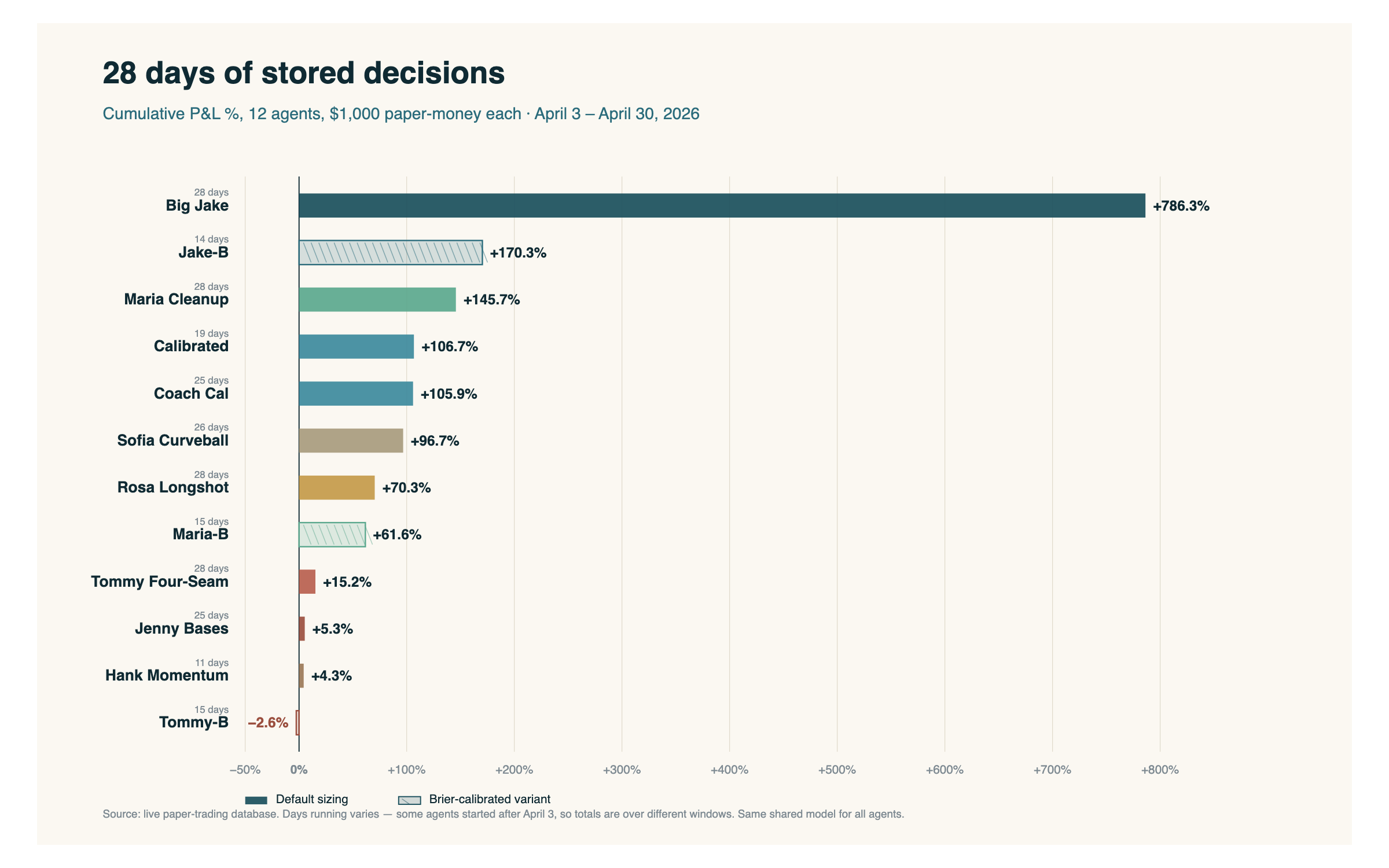
After 28 days, 11 of the 12 agents are in positive territory. Across the whole roster, the agents settled 1,383 picks and skipped 19,555. That's roughly 14 skips for every pick. The combined paper-money pool of $12,000 is up by $15,657 in aggregate. The agents are right less often than they are wrong (47.7% on settled picks), but the average winning pick is about 1.5× larger than the average losing one, so the math still goes their way.
Big Jake is the loud story again. Everyone else is the quieter one. Both are real. Last week the bottom of the chart had a few agents underwater on small samples. This week, with another seven days of decisions and the late-starters catching up, only Tommy-B is still red, and barely.
The rest of this post is about the working relationship that produced all of that.
The shape of it
Two repos hold the experiment. Between them:
- About 75,000 lines of code. 57 Python files in the engine that runs the simulated agents, 130 TypeScript and React files in the web app.
- 109 commits between March 31 and April 21.
- 106 of those 109 end with a footer that says
Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>.
That footer is not there for legal reasons. It's there because the whole point of this experiment is to see if one person plus AI can do the work of a small team. If that's the claim I'm making, the only way the claim means anything is if I'm honest in the git log about who did what. I want the credit to live in the artifact, not just in the blog post.
Where Claude Code carries weight
Four places, with examples.
The RAG synthesis layer. Roughly 200 lines of code that wrap the Anthropic SDK and do per-game news analysis. Cost tracking, structured output, sensible defaults, error handling. Claude wrote the whole thing in one pass. (Last week's post is mostly about what this layer does.)
The decisions table. Twenty-eight columns of Postgres that capture every agent's call on every game on every slate: which agent, which game, the structured signal, the unstructured signal, the decision, a short free-text reason, and after the game finishes, the result and the CLV. I designed it. The schema, the migrations, the reads and writes are all Claude.
The feature pipeline. Six modules that compute roughly 90 quantities per game from MLB Stats API, weather, odds, and historical box scores. Elo with pitcher adjustments, walk-forward training windows, no lookahead. I described what I wanted. Claude wrote the code that ran.
The full SaaS surface, built fast to lock in the pivot. This one matters the most on the list and it needs some context. In Post 2 I called the move from a real-money agent to a no-money game-of-agents the strategic reset of the project. A reset like that needs somewhere to live. You can't announce a pivot if the new product doesn't exist yet. So I gave it three days.
From a git init on April 10 to the end of April 12, the app went from nothing to: working auth (Google-only), an agent-builder page with an AI coach and a live preview, a dashboard with daily picks, a leaderboard, head-to-head scout comparison, pick history, shareable cards with dynamic OG images, Stripe billing with webhooks and a customer portal, an anti-abuse layer (device fingerprinting plus disposable-email blocking plus IP rate limits), CCPA, FTC click-to-cancel, EU AI Act Article 50 compliance, a CI pipeline with unit and e2e tests, and the seventeen small bug-fix commits in between. The one I remember most fondly: "fix: trim Stripe API key to prevent newline in header."
Forty-one commits in three days. The strategic decision was mine. The shipping was a co-author's. Neither of those happens without the other.
Where I carry weight
Four places, just as concretely.
The idea, and the strategic moves under it. The premise of this whole thing — baseball, agents that learn over time, a gamified arena instead of a picks subscription, the thesis that one person plus AI can do the work of a small team — that's mine. The pivot from a real-money agent to a no-money game (Post 2) was a call I made after weeks of running the agent on paper-money and reading enough gaming-law to understand what surface I was on. A model doesn't make those moves. A model can also make them go sideways if you let it optimize for "best practice" instead of the right thing for this specific project.
The architecture. The choice to run the whole back-end as one Postgres database and one Python process on Railway, no microservices, no queues, no workers, is mine. The choice to build the agent's intelligence as two halves, a structured model plus an unstructured LLM that mostly stays quiet, is mine. And so is the memory layer: a vector-indexed table that stores every agent's decisions, picks and skips, so each agent can learn from its own history, and one day from the histories of the other agents on the roster. Claude wrote the code for all of that. I wrote the design memos that made the code necessary.
Vendor and trade-off decisions under pressure. In mid-April, FanGraphs started returning 403 errors on cloud IPs. The model I was training depended on it. The commit message for the fix reads, word for word:
Replace FanGraphs with MLB Stats API for batting and pitching data. FanGraphs blocks cloud IPs with 403. MLB Stats API is free, no auth, no IP restrictions, and returns all 30 teams in one call. Computed stats: FIP from raw components, wRC+ approximation from OPS+ style formula, K%/BB%/ISO from counting stats.
Claude wrote that swap. The decision to swap instead of paying for FanGraphs enterprise was mine. The decision to retrain the ensemble on the new feature set instead of shipping it with NaNs in the batting columns was mine. The judgment about how much accuracy I was willing to trade was mine. Those one-paragraph diagnoses with a direction at the end of them are the part I have to produce for myself, before any code gets written.
Product nomenclature, taste, and saying no. The agent-builder levers are called Swing Size, The Leash, Tap Out Tolerance, Cherry Pickerness, and Swagerness. Those names came from me. They are the kind of judgment — what's playful, what's clear, what reads as a real product and not an engineering project — that I don't think an AI should be making, at least not on this project and in this voice. And the same is true of the most useful thing I do most days, which is to say no to ideas. Some of the no is taste: that's not the product. Some of it is sequence: that's the right idea three months from now, not today. Some of it is honesty about scope: I don't have the bandwidth for a third surface. Claude is excellent at how once what is decided. What is still mine.
Two operating rules I've landed on
Working this way at this scale has surfaced two simple rules that I now treat as important.
Tell it what it doesn't know. The app repo has an AGENTS.md file at the root. It reads, in full:
This is NOT the Next.js you know. This version has breaking changes — APIs, conventions, and file structure may all differ from your training data. Read the relevant guide in node_modules/next/dist/docs/ before writing any code. Heed deprecation notices.That short paragraph saves me hours every week. Claude Code is trained on a snapshot of the world. The world has moved on. The snapshot is wrong about the most common things first, which is the worst possible combination. The fix is not to argue with the model after it confidently wrote outdated code. The fix is to tell it, before it writes a line, where the training data is stale and where to find the truth instead.
Per-repo trust boundaries. Each repo has its own .claude/settings.local.json that pre-approves a specific list of shell and tool patterns. The agents' engine repo trusts the Railway CLI and a couple of research-fetch domains. The app repo trusts the Vercel CLI, Prisma migrations, npm installs, and a small set of git operations. Neither repo trusts the other's tools. Neither one trusts anything destructive without me in the loop.
"Give the AI tools" and "give the AI my tools" are two very different sentences. I want the model running with the smallest set of permissions that still lets the work get done. Five minutes to write that allowlist buys me a lot of peace of mind. The per-repo split also means that if Claude tries to use an unfamiliar tool in the wrong context, I get a prompt instead of a silent execution.
The compounding effect, and its cost
One thing about this kind of velocity: it compounds in directions you didn't budget for.
Three days of compliance work, in the wrong order, would have taken me three weeks. With a co-author who can read the FTC Negative Option Rule and turn it into a cron schedule, it took three days. That's the upside.
The downside is that those three days of compliance work still had to happen. The legal and regulatory surface of a consumer SaaS, even a free one, even a side project I'm doing on a personal-finance budget, is bigger than I expected. Every layer I found was its own surprise. That's next week's post.
Why the footer matters
I don't want anyone reading this series to walk away thinking I built a 75,000-line system in five weeks by myself. I didn't. I built it with a model. The model wrote a lot of the code. I wrote the design, the architecture decisions, the prompts, the no's, and the small handful of moments where the project either lives or dies. The git log says exactly that on almost every commit, in a format anyone with git blame can check for themselves.
That's the part of this experiment I'm most committed to keeping honest. The thesis only means something if the accounting under it is real.
Next week
Post 5 is the legal and compliance surface I didn't see coming. The real-money-to-no-money shift, gaming-law adjacency, IP and ownership questions when AI is in the loop, and the specific surprises that ate that April compliance week.
If you've been working in this mode and you'd draw the line in a different place than I did, I'd like to hear it.
Previously in this series: Week 1 — the genesis · Week 2 — the pivot (the receipts) · Week 3 — the data stack.
These are personal notes from a side project I do on my own time with my own resources. The views here are mine and are not connected to, endorsed by, or representative of my employer or any of my professional work.



