I taught an LLM to say nothing most of the time.
Week 3 of a 10-week build-in-public series. The data stack — and why the noisy half is where the system either earns its keep or breaks.


A week ago, I said this thing wasn't a betting agent anymore — it was an arena where you build agents and watch them compete. The agents are the front of the house. This post is about the back: the data they see, and the mechanism that lets each agent learn over time from its own decisions — the way a human would.
The version that survived has simulated agents, each with their own parametrization, that make a Claude call on every game on the slate. Most of the time, that call comes back saying nothing. That's not a bug. That's the design.
Three weeks in
Before getting into the back-end, here's where the agents stand after the first three weeks of paper-trading.
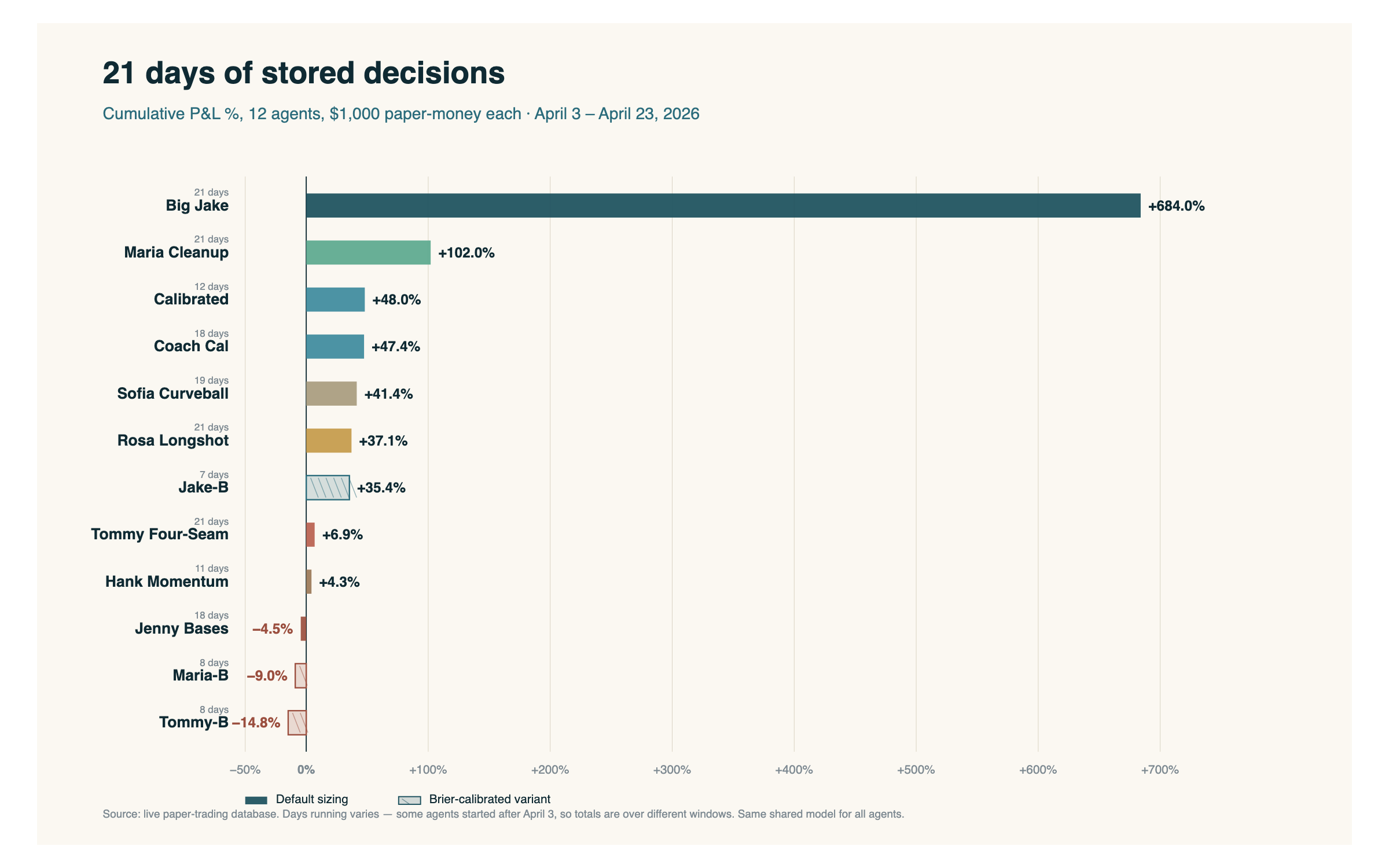
12 agents, the same shared model behind all of them, different sizing and selection rules. Some agents started later than April 3, so their totals are over shorter windows — that's the back-calc note, marked on the chart for honesty. Big Jake's run is the loud story. The bottom of the table — same shared model, real negative numbers — is the quieter one.
The rest of this post is about the back-end that produces those numbers: the data the agents see, and the mechanism that lets each of them learn over time from its own decisions.
The two halves the agents have to combine
Each agent must combine two very different kinds of inputs to make a call.
Structured. Box scores, rolling stats, odds, weather, ratings. Numbers in, numbers out. Stable schemas, honest arithmetic, an XGBoost ensemble at the end of it.
Unstructured. Beat-writer news, injury notes, lineup tweets, transactions. Noisy in the way that cannot be schematized away — most "news" is chatter, the genuine signal is rare, and a system that treats every headline as material gets whipsawed into garbage.
The whole game is combining the two. The structured side gives the agent a probability. The unstructured side either confirms it or quietly tells the agent to size down.
This is the part that genuinely amazes me about the current generation of AI. Sifting through a pile of mostly-noise text — beat-writer takes, lineup tweets, transaction logs — to find the one fact that matters for one specific game is the kind of work that used to either require an analyst per slate or just didn't get done. What I want you to notice here isn't a claim about how good the model is at it — whether it's finding the right diamonds, and how often, is exactly what I'm still measuring. It's that the model is fast and cheap enough to attempt the work systematically at a personal-finance budget: every game, every day, in seconds, for cents. The capability is operational reach, not proven judgment. The judgment is what the rest of the system is built to keep honest.
Where the whole thing runs
Before getting into either half, it's worth saying where this all lives, because it's deliberately simple.
The entire back-end is two things:
- One Postgres database on Railway (a developer-friendly cloud platform for hosting apps and databases), with the
pgvectorextension turned on so the same database can hold both relational tables and embedding vectors. - One Python process that runs everything else — a single web service whose entry point starts a scheduler in the background and a small dashboard in the foreground. APScheduler is the cron-equivalent inside the process; it fires the daily jobs on a fixed UTC heartbeat.
That's it. No microservices, no message queues, no separate workers. The whole pipeline — fetch the day's stats, fetch the day's news, build the feature vectors, run model predictions, synthesize the unstructured signal, evaluate every agent against every game, log every decision — runs as a sequence of jobs inside that one process, in the same order, every day.
There's a reason for the simplicity beyond cost. When the whole back-end is one process and one database, every problem has exactly one place to look. Most of the friction in this project has been about making decisions cleanly, not about debugging distributed plumbing.
My philosophy as a builder is to keep things simple. Or as simple as I can make them.
The structured half
A handful of free or near-free sources feed this side: the official MLB Stats API for schedule, lineups, and team-level stats; The Odds API for live market odds; Open-Meteo for game-time weather; and historical game logs for training and rolling computations.
The pipeline turns those into 90+ inputs per game — basically every quantifiable thing a serious fan would think to look at before a game, plus a few they wouldn't.
There's one design decision in here worth flagging because it's the kind of thing that quietly destroys models: every feature is computed strictly from data available before the game. No lookahead. The training loop is walk-forward — train on the first batch of games, predict the next, slide forward, retrain. It's slower and less impressive-looking on backtests than the alternative, and that's exactly why it works.
The hard half (news)
The unstructured layer is the part where most "AI in sports" projects either skip the work or wave their hands about it. Here it does real work, but a deliberately narrow kind.
A scheduled job pulls news from a small set of trusted sources twice a day, in the window before pre-game lines firm up. The articles get embedded and stored alongside the rest of the data, so for any given game the system can pull the handful of items that actually mention the teams or pitchers involved.
Then, for each game on the slate, Claude reads that small bundle and answers exactly one question: given what the structured model already knows, does this news warrant adjusting how confidently we'd act on the model's call?
The answer is not a pick. It's not a probability. It's a small structured signal that can leave the model's call alone, scale it down, or in extreme cases stop it entirely. The LLM cannot pick a side. It can only attenuate.
The conservative design
The whole layer is conservative on purpose. The design is built around one idea: most news is not news, and a model that doesn't know how to ignore noise is just noise.
So the LLM has narrow authority. It cannot strengthen a call, only reduce or block it. The maximum reduction is small — a fraction, not a flip. And its default state is silence: if there isn't a clear, material reason to say something, the right answer is to say nothing.
The agent's memory is part of the data stack
This is the part that's the most fun to think about, and it's one of the bigger unexpected learnings of the experiment so far.
The same database also stores what each agent decided, why, and what happened. Every time an agent evaluates a game — pick or skip — a row goes in: which agent, which game, the structured signal, the unstructured signal, the decision, a short free-text reason summarizing the call, and (filled in after settlement) the outcome.
The skips matter as much as the picks. That's where most systems lose memory.
This was a decision I had to make: store every game decision, or only the ones the agent picked? At the end of the day this is an experiment. I want to try as many things as possible with AI in the loop — AI and me, both learning along the way. And for AI to learn, one thing you need is good data, and a lot of it. So I'm collecting the skip games too, as a source of learning. The idea isn't only to make sure we picked the right games (true positives) — it's also to minimize the chance of not picking a good one (false negatives). That's the other half I'm trying to capture by saving every single decision by every single agent.
The reframe
Most of the talk around LLMs spends a lot of time on what they can't do: they don't remember across calls, they don't learn from outcomes, they don't accumulate experience the way a person does. Working on this experiment has made me think those aren't limitations — they're opportunities. The model doesn't have to remember anything if the system around it does. The agent's memory doesn't have to live in the model. It can live in a vector database, and you can hand the relevant slice of it back to the model at decision time.
In other words, the experiment gist is: build the part the LLM lacks, and the LLM gets to use it like it had it all along. That's it. That's the "Unlock" hypothesis.
A direction I want to chase
If one agent can learn from its own track record this way, why couldn't an agent learn from another agent's? They all work for the same person. There's no reason Big Jake couldn't share a hard-won lesson — "this kind of game looks like a layup but I keep getting clipped on it" — with another agent on the roster. The substrate's the same; you'd just have to decide what counts as transferable knowledge and what's specific to one agent's style.
That's not built. It's in the research queue. But it's the kind of synergy that only really makes sense once the memory layer exists in the first place — and the memory layer is the thing this whole section is about.
Why the split works
Two reasons.
Separation of concerns. The structured model is responsible for "what's the probability this team wins, given everything quantifiable." The LLM is responsible for "is there confirmed qualitative information the model couldn't see." These are different jobs and they should have different decision authorities. The model picks. The LLM only objects.
Auditability. Every synthesis result is stored. Every decision is stored with the inputs that drove it. When something works or breaks, I can read exactly what the system thought it was seeing. The prompts and thresholds get edited on contact with reality, not on vibes.
What this all costs
Most of the data sources are free or close to it (MLB Stats API, Open-Meteo, RSS), with NewsAPI on a free dev tier. The only meaningful per-call cost is the Claude synthesis layer at roughly $0.13/day for a full slate of games — under $5 a month for the LLM piece. Add the small Postgres + single-web-process bill on Railway and the whole stack runs on less than a sandwich a week, not a sandwich a day.
Next week
Post 4 is about working with Claude Code as the primary engineer on this thing. I called out one specific moment above where Claude carried real weight — the conservative-by-design RAG layer the system runs on. Next week is the full picture: where the AI is genuinely doing the work, where I am, and where the line keeps moving.
If you've built something with a similar shape — structured model + LLM as a quiet filter, plus a memory layer for the system's own decisions — I'd like to compare notes.
Previously in this series: Week 1 — the genesis · Week 2 — the pivot (the receipts).
These are personal notes from a side project I do on my own time with my own resources. The views here are mine and are not connected to, endorsed by, or representative of my employer or any of my professional work.



